HiMat: DiT-based Ultra-High Resolution SVBRDF Generation
Zixiong Wang, Jian Yang, Yiwei Hu, Miloš Hašan, Beibei Wang

Figure 1: We present HiMat, a diffusion-based framework generating ultra-high-resolution (4096 × 4096) SVBRDF materials from text prompts. Our approach achieves this resolution while preserving high-frequency details crucial for meso-structure components such as normal and height maps. We showcase a variety of materials within a single scene, highlighting the preserved fine-scale details and texture fidelity.
Abstract
Creating ultra-high-resolution spatially varying bidirectional reflectance functions (SVBRDFs) is critical for photorealistic 3D content creation, to faithfully represent fine-scale surface details required for close-up rendering. However, achieving 4K generation faces two key challenges: (1) the need to synthesize multiple reflectance maps at full resolution, which multiplies the pixel budget and imposes prohibitive memory and computational cost, and (2) the requirement to maintain strong pixel-level alignment across maps at 4K, which is particularly difficult when adapting pretrained models designed for the RGB image domain. We introduce HiMat, a diffusion-based framework tailored for efficient and diverse 4K SVBRDF generation. To address the first challenge, HiMat performs generation in a high-compression latent space via DC-AE, and employs a pretrained diffusion transformer with linear attention to improve per-map efficiency. To address the second challenge, we propose CrossStitch, a lightweight convolutional module that enforces cross-map consistency without incurring the cost of global attention. Our experiments show that HiMat achieves high-fidelity 4K SVBRDF generation with superior efficiency, structural consistency, and diversity compared to prior methods. Beyond materials, our framework also generalizes to related applications such as intrinsic decomposition.
Method Overview
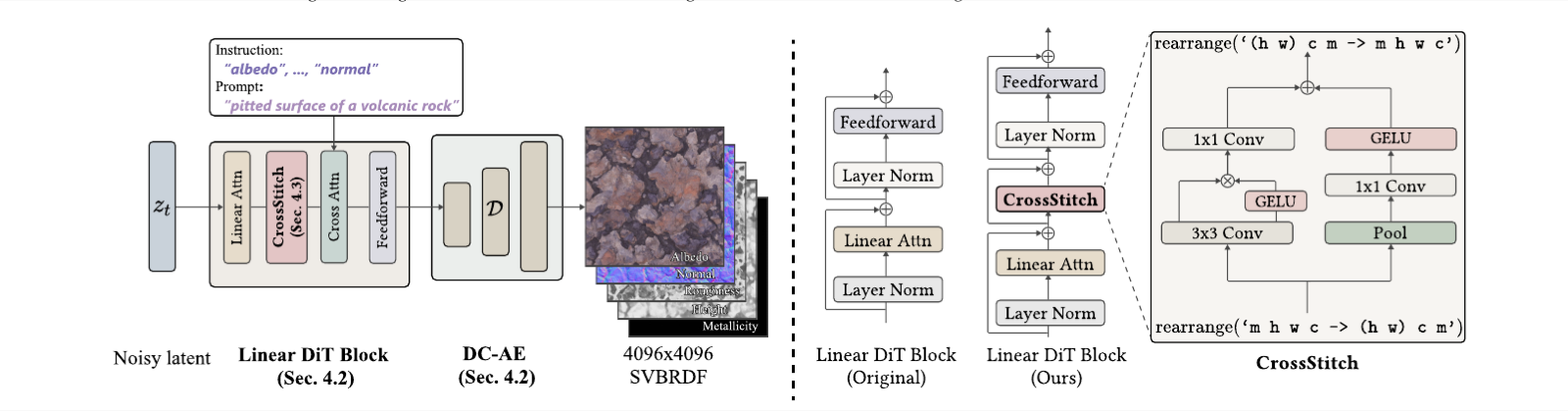
Figure 2: Overview. Left: Given text instructions, our framework generates 4K SVBRDF maps through a latent denoising pipeline based on linear DiT (Sec. 4.2), with outputs reconstructed by a deep compression autoencoder (DC-AE) (Sec. 4.2). CrossStitch layers (Sec. 4.3) are integrated into the linear DiT block after each linear attention layer. The combination of linear DiT and DC-AE enables efficient ultra-high-resolution generation, while the CrossStitch design ensures consistency across maps. Right: Architecture of our modified DiT block (cross-attention omitted for clarity). A lightweight convolutional CrossStitch module enables localized feature exchange across maps, ensuring pixel alignment.
Our goal is to train a diffusion-based SVBRDF generator that produces 4K materials from text prompts. High-quality generation requires efficiency, diversity, and consistency across reflectance maps. The key challenges are twofold: (1) each map must be generated at full 4K resolution, and the presence of multiple maps multiplies the pixel budget, leading to prohibitive memory and computational cost, and (2) the maps are physically interdependent and must remain pixel-aligned at 4K, a requirement that is particularly difficult when adapting pretrained image models designed initially for 3-channel RGB inputs rather than multi-channel SVBRDFs.
To address these challenges, HiMat employs a high-compression autoencoder (DC-AE) and a linear-attention diffusion transformer to reduce the effective pixel budget for 4K SVBRDF, substantially lowering memory consumption and computational cost. To address the second issue, HiMat introduces the CrossStitch module: a lightweight convolutional layer integrated into each linear DiT block that enforces cross-map consistency without incurring the cost of global attention.
Results
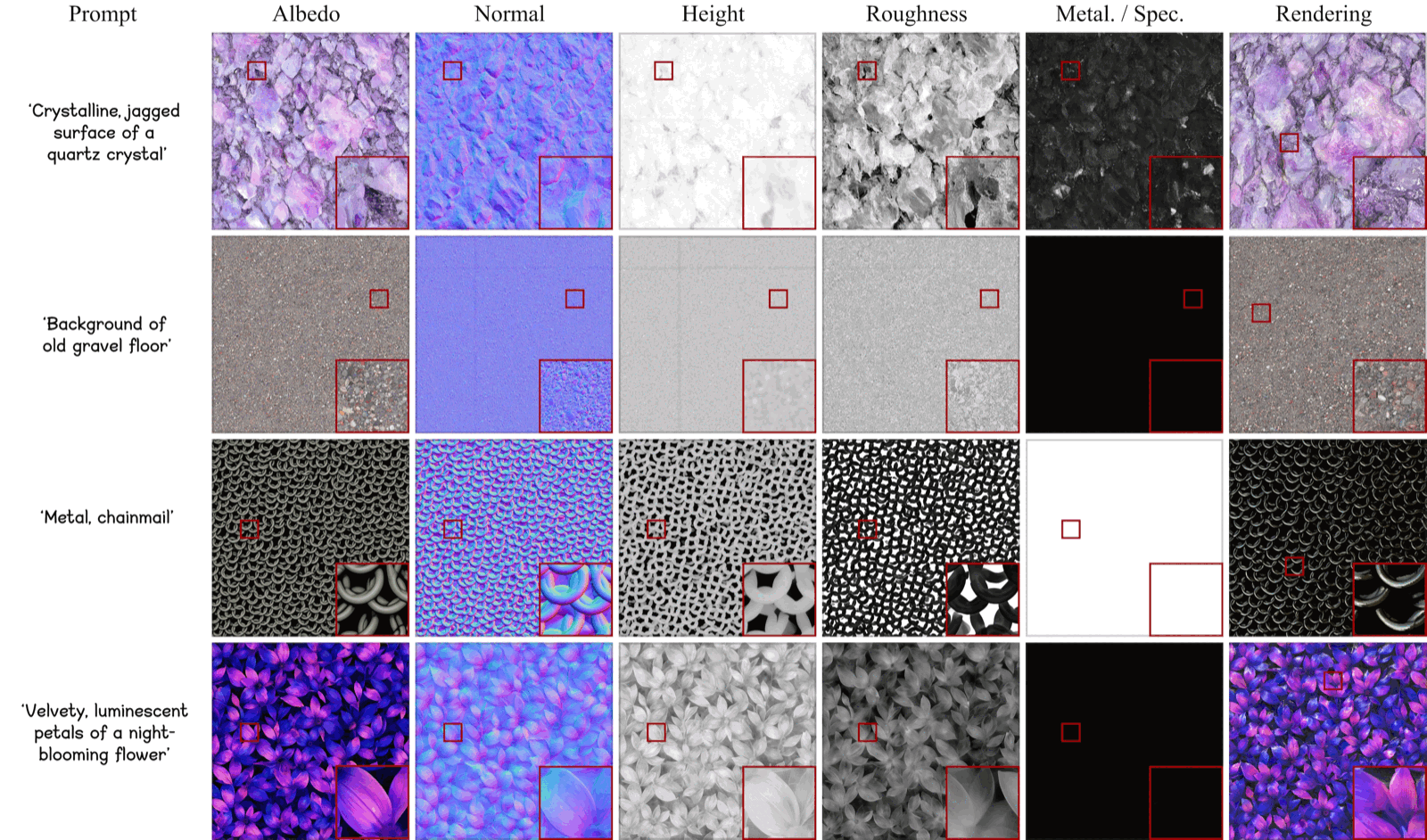
Figure 7: Additional visual results from HiMat. These examples further demonstrate the diversity, realism, and fine structural details achieved by our method.
Comparison

Figure 5: Visual comparison between HiMat, ReflectanceFusion [Xue et al. 2024], and MatFuse [Sartor and Peers 2023]. ReflectanceFusion exhibits baked-in lighting artifacts and is limited to a resolution of 256 × 256. MatFuse suffers from reduced realism and diversity due to training exclusively on synthetic data at 512 × 512 resolution. In contrast, HiMat delivers high-quality 4K materials with fine detail. A slightly tilted camera view is employed in the rendering to visualize the details better.
Citation
@article{wang2026himat,
title = {HiMat: DiT-based Ultra-High Resolution SVBRDF Generation},
author = {Wang, Zixiong and Yang, Jian and Hu, Yiwei and Ha{\v{s}}an, Milo{\v{s}} and Wang, Beibei},
journal = {Computer Graphics Forum (Proc. Eurographics)},
year = {2026},
month = mar,
doi = {10.1111/cgf.70343},
publisher = {Wiley}
}